Defending Against Malicious Behaviours in Federated Learning with Blockchain
TLDR
- Currently, Federated Learning is primarily implemented by a select group of tech giants, but this centralised approach presents challenges in protecting against malicious attacks.
- Blockchain technology can help overcome this by: enabling decentralised consensus, and incentivising honest behaviour among users using proof of stake (PoS) mechanisms.
Sections
- Federated Learning: Machine learning without data collection
- Use Blockchain for Decentralised Consensus
- Proof of Stake (PoS) for Game Theoretic Security Guarantee
Federated Learning: Machine learning without data collection
Centralised machine learning raises data privacy and security concerns. This is because personal data is not controlled by individuals, and there is risk of unauthorised access, use, or destruction of data. These concerns are prevalent across industries:
- In 2022, Chinese electric car maker Nio Inc.’s computer systems were hacked. Hackers accessed data on users and vehicle sales, and demanded a $2.25 million bitcoin ransom for the company’s internal data.
- In 2022, Medibank, an Australian health insurance company, also suffered a data breach. Cybercriminals accessed the personal and medical data of around 9.7 million customers after their refusal to pay a demanded ransom.
The anonymisation of user data is widely adopted to address security and privacy concerns. However, it remains prone to re-identification attacks. Such attacks can re-identify individuals from anonymised data by matching it to publicly available information: for example, names, addresses, or other identifying information found in public records or social media.
Another potential issue is bias in centralised machine learning systems. If training data is not representative of the entire population, the resulting model may be biased and make unfair or inaccurate predictions about certain groups of people.
- In 2020, Google AI researchers Margaret Mitchell and Timnit Gebru criticised the way the company’s AI system was being developed. Their paper on the potential ethical ramifications of the technology was asked to be retracted, and they were both dismissed by Google.
Federated Learning is a promising solution where “source data stays at source”. It allows a model to be trained in local devices, rather than a central server; updates from local models are aggregated to create a global model.
However, Federated Learning has pitfalls. Currently, only tech giants can implement federated learning at scale due to model security concerns and coordination efforts.
- Central coordination: It’s a complex process to coordinate the training process across a decentralised network of devices, monitor participation, and distribute rewards to incentivise participants — the manual process is a main blocker, and using blockchain can automate it.
- Model security: Federated Learning can be vulnerable to malicious attacks intending to harm the learning process or the privacy of other participants. Bad participants can deliberately send incorrect or inconsistent data or gradients to other participants during the learning process, causing the model to be inaccurate. They might also poison the data by injecting malicious or misleading data into the shared model, causing it to make incorrect predictions.
In the next sections, we will discuss how blockchain technology can mitigate the coordination and security challenges in Federated Learning by 1) enabling decentralised consensus and 2) implementing a Proof of Stake system to incentivise participants.
Use Blockchain for Decentralised Consensus
Blockchain technology can mitigate the coordination challenges in centralised Federated Learning by enabling decentralised consensus.
A blockchain is a decentralised computer system that keeps a record of digital transactions and is not controlled by any one person or organisation. The concept was first popularised by Bitcoin, the first and most widely used cryptocurrency, and now a plethora of decentralised applications run on Ethereum.
Blockchain can function as a “trust engine” without centralised coordination. No single entity controls it and all users have access to the same information cryptography ensures that the information stored on it is secure and cannot be altered or tampered with. Users can securely and transparently exchange information and conduct transactions without needing to trust each other.
Decentralised consensus is a way of making sure that everyone agrees on the information being used and shared. It gives more people control over their data and makes it harder for others to misuse or steal it. This approach also allows more people to take part in training computer models, which makes the models more diverse and better.
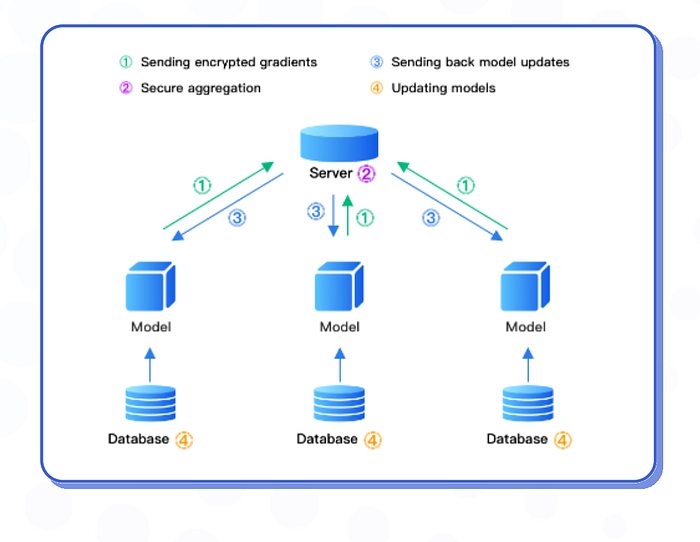
In traditional Federated Learning, a central server receives local updates, aggregates them into a global model update, and then sends updates to local clients.
Centralised FL
In traditional FL set-ups, models are trained locally and only model updates are shared with the server. Raw data stay local. The server receives local updates and sends back aggregated updates.
On-chain FL
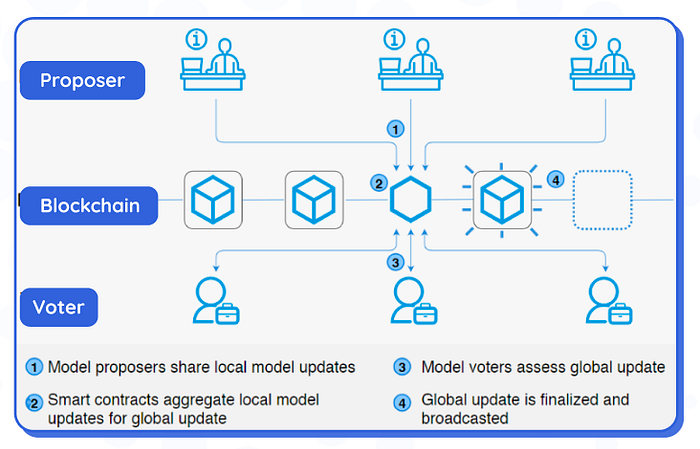
Our proposed on-chain solution uses smart contracts to aggregate updates. A smart contract is a computer program that can automatically execute the terms of a contract when certain conditions are met. It is self-executing because it can automatically enforce the rules and penalties of an agreement, without the need for a middleman.
With the on-chain solution, the model does not need to trust a centralised server. The proposers conduct local training and send model updates on-chain, and then the on-chain smart contract runs a FedAvg (a weighted average of local updates).
On-chain Security Guarantee Using Game Theory
The quality of local outputs is determined in the peer-to-peer validation process. Participants partition their data for training and testing before the training process started.
In each round of training, participants are randomly selected to be proposers or voters. If the latter, the voters run the aggregated update on their test data to assess whether the update improves their performance. The collective vote determines whether the aggregated update gets finalised or not — for example if over half of the voters voted against it, the update isn’t finalised and the system restarts this round of training (goes back to the proposer/voter selection stage).
The decentralised validation mechanism is not only ‘democratic’, but more secure. If there is only a central party determining the quality of the output, it is easier for malicious proposers to learn its criteria and incorporate them into the loss function.
Based on the collective vote, proposers are rewarded/slashed, which enables the system to filter out malicious clients. All proposers are required to put down enough stake to participate. If the global update lowers model performance, all proposers will be slashed; in the multi-round training process, malicious clients are far more likely to appear in rounds with deteriorating performance than benign ones.
In other words, if a proposer wants to bring down model performance, they are more likely to get slashed. We adjust the system parameters (staking threshold, reward/slashing ratio) such that malicious clients are filtered out (stake drops below zero) while the expected return for benign clients is greater than zero.
The multi-round training process is essentially a multi-round game, using the right parameters(determined in simulation), it filters out malicious clients in an automated way.
